



Explorative Datenanalyse
Sei es die Auswertung eines DoEs (Design of Experiments), von Prozessdaten oder die Suche nach einem guten Modell für einen Datamining-Wettbewerb: Die wichtigste Basis für eine erfolgreiche Datenauswertung ist es die Daten so gut wie möglich zu verstehen.
Dabei spielt Fachwissen natürlich eine große Rolle. Mindestens genauso hilfreich ist allerdings eine detaillierte explorative Datenauswertung. In diesem Blogpost werde ich einige typische Fragestellungen der Explorativen Datenanalyse (EDA) behandeln und gängige Werkzeuge vorstellen um diese Fragen zu beantworten.
Dabei fokussiere ich mich dieses Mal auf die univaraite Betrachtung von Daten anhand von Histogrammen und Balkendiagrammen. Besonders möchte Ich dabei zeigen wie viel unterschiedliche Informationen sich oft schon aus diesen einfachen Grafiken ableiten lassen.
Das Beispiel: Prognose von Einkommen
Für diesen Blogeintrag beschäftige ich mich mit einem beliebten Datensatz aus dem Bereich des Datamining. Auf der Webseite des UCI Machine Learning Repository finden sich zahlreiche Beispieldatensätze zum Thema Datamining/Data Science/Knowledge Discovery in Databases. Im Folgenden werde ich mit dem Adult-Datensatz arbeiten. Er enthält verschiedene demographische Daten von erwachsenen US-amerikanischen Bürgern aus dem Zensus von 1994. Ziel ist es anhand von diesen Informationen vorherzusagen, welche Personen ein Jahreseinkommen >50.000$ haben.
Ein erster Überblick
Ja nach Art des Datensatzes und der jeweiligen Fragestellung sieht eine EDA oft sehr unterschiedlich aus. Ganz am Anfang stehen aber dennoch oft sehr ähnliche Fragen:
- Welche Variablen gibt es?
- Welches Skalenniveau haben die einzelnen Variablen?
- Gibt es offensichtliche Fehler in den Daten?
- Gibt es potentielle Ausreißer?
Ein einfacher Weg sich darüber Klarheit zu verschaffen ist es sich die einzelnen Variablen als Histogramm (bei stetigen Variablen) bzw. als Balkendiagramm (kategoriale Variablen) anzusehen.
#--------------------------------------------+
# Explorative Data Analysis: Adult Data
#--------------------------------------------+
library(ggplot2)
# Import
adult = read.csv("https://archive.ics.uci.edu/ml/
machine-learning-databases/adult/adult.data", header = FALSE)
head(adult)
# Add column names
colnames(adult) = c("age", "work_class", "fnlwgt", "education",
"education_num", "marital_status", "occupation",
"relationship", "race", "sex", "capital_gain",
"capital_loss", "hours_per_week", "native_country", "y")
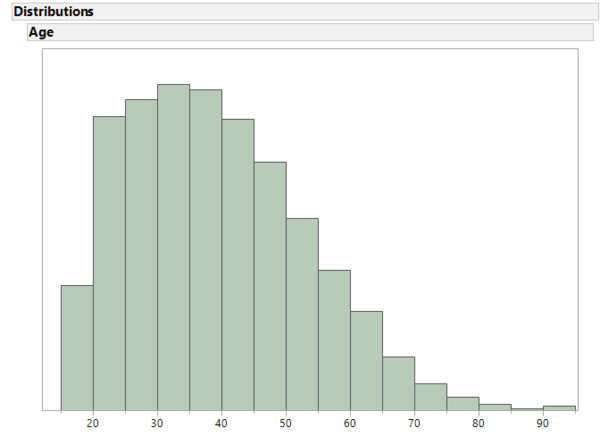
# Überblick: Alter Histogram
ggplot(adult, aes(x=age)) +
geom_histogram(binwidth = 8, color="white") + # Control Binwidth
scale_x_continuous(breaks=seq(0, 100, 10)) # Adjust X-axis-ticks
# Libs
import pandas
import requests
import matplotlib.pyplot
matplotlib.style.use('ggplot')
# Load data from web
adult_train_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
adult = pandas.read_csv(adult_train_url)
# Add Column Names
adult.columns = ["age", "work_class", "fnlwgt", "education",
"education_num", "marital_status", "occupation",
"relationship", "race", "sex", "capital_gain",
"capital_loss", "hours_per_week", "native_country", "y"]
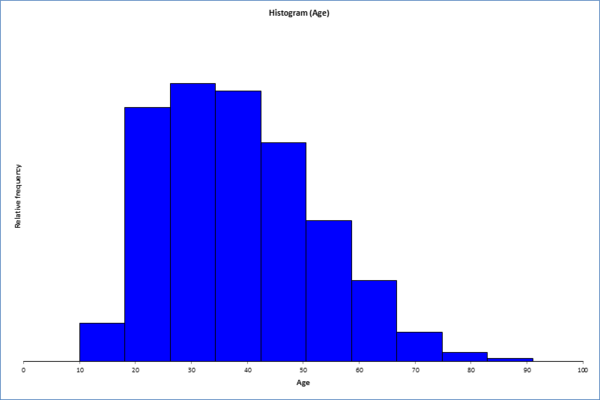
# Plot Histogram of 'age'
adult['age'].hist()
Für die Altersverteilung gibt es keine besonderen Auffälligkeiten. Offensichtlich wurden keine Kinder in den Daten berücksichtigt. Sonst entspricht die Verteilung dem was wir von einer Industrienation erwarten können.
Betrachten wir nun eine weitere Variable: capital-gain. In der Beschreibung der Daten steht nur, dass es sich hier um eine stetige Variable handelt. Da der Name selbst nicht unbedingt selbst erklärend ist können wir hoffen, dass die Daten für sich selber sprechen:
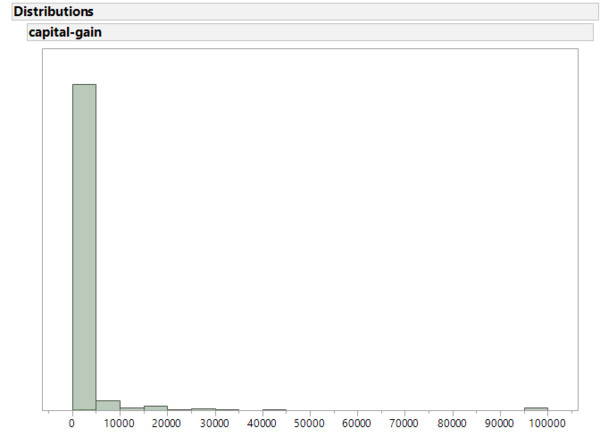
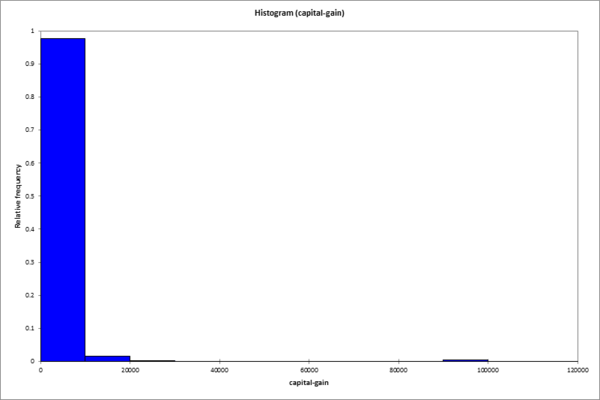
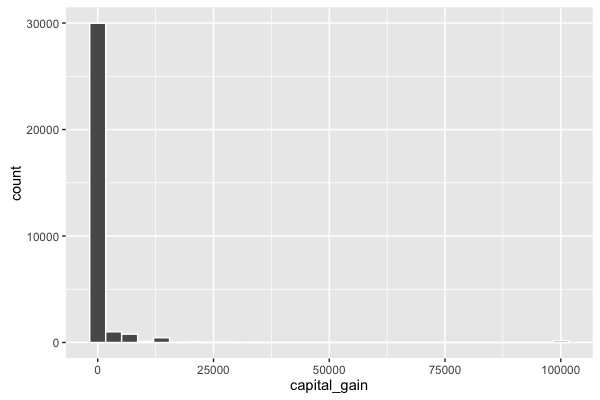
# Überblick: Capital gain histogram
ggplot(adult, aes(x=capital_gain)) +
geom_histogram(color="white")
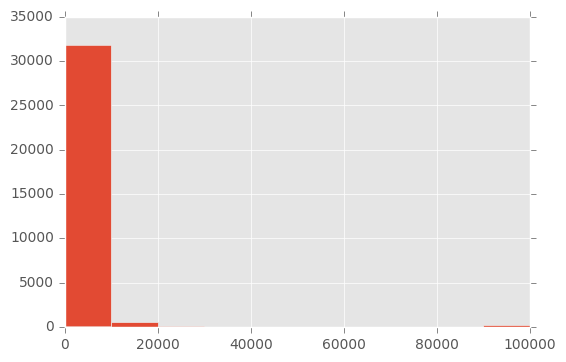
# Überblick: Capital gain histogram
adult['capital_gain'].hist()
Die vorliegende Art von Histogramm sieht man recht häufig, insbesondere wenn die Daten bereits aufbereitet wurden. Es gibt auffällig viele Nullen in der Variable. Hier muss man davon ausgehen, dass zumindest einige 0-Werte eigentlich einen fehlenden Wert (NA) repräsentieren.
Ausserdem gab es eine Reihe von Personen, die mit 99.999 geantwortet haben. Im Histogram erscheinen diese Fälle nur als minimaler Balken. Tatsächlich sind es 159 Personen, die für capital_gain 99.999 angegeben haben. Es stellt sich hier die Frage wie die Daten erhoben wurden und ob 99.999 nicht eigentlich für eine Kategorie ">99.999" steht.
Im Rahmen der explorativen Datenanalyse müssen wir uns noch nicht damit beschäftigen, wie wir mit diesen Problemen umgehen. Es ist jedoch nützlich sie zu dokumentieren und sie vor der Modellierung gegebenenfalls zu behandeln.
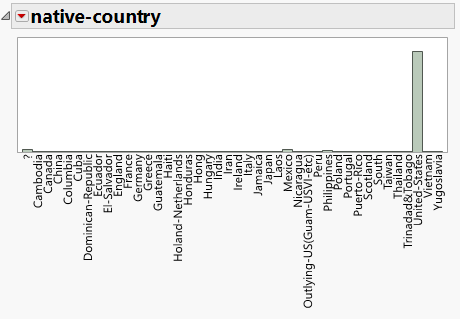
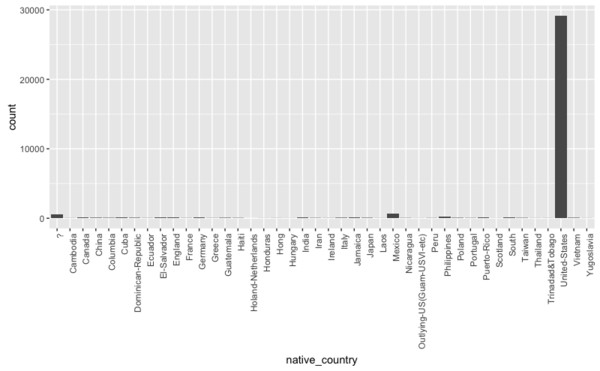
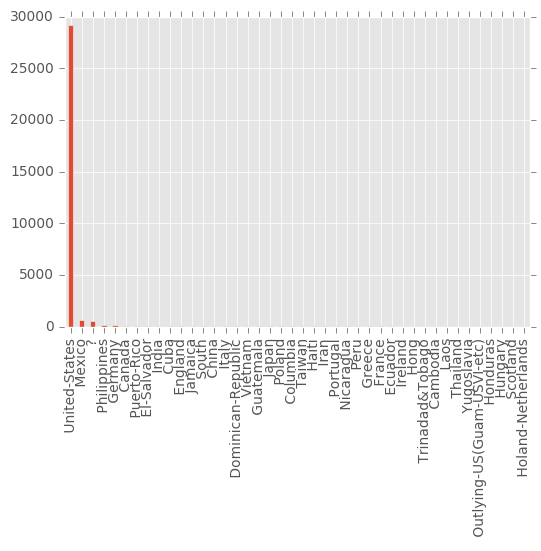
Werfen wir nun stellvertretend für die verschiedenen kategorialen Variablen einen Blick auf native-country:
ggplot(adult, aes(x=native_country)) + geom_bar() +
theme(axis.text.x = element_text(angle = 90, hjust = 1))
# Plot a barchart of 'native_country'
adult['native_country'].value_counts().plot(kind='bar')
Auch hier fallen zweierlei Dinge auf:
- Es gibt eine Kategorie "?". Diese sollte vermutlich zu fehlenden Werten umkodiert werden.
- Fast alle Daten stammen aus der Kategorie "United-States".
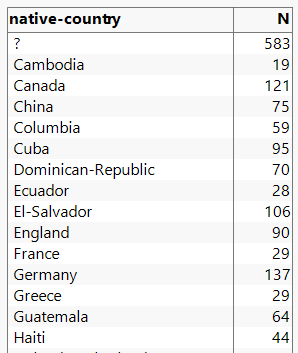
Während das erste Problem in den meisten Programmen einfach zu lösen ist, stellt Letzteres eine größere Schwierigkeit dar. Verschafft man sich einen Überblick über die konkreten Fallzahlen stellt man fest, dass für verschiedene Nationalitäten oft nur wenige Fälle im Datensatz vorkommen.

ggplot(adult, aes(x=native_country)) +
geom_bar() +
theme(axis.text.x = element_text(angle = 90, hjust = 1))

adult['native_country'].value_counts()
Es stellt sich also die Frage, ob eine Aussage - und gegebenenfalls eine Prognose - anhand von 28 Personen aus Ecuador gemacht werden soll/kann. Eine mögliche Lösung wäre es verschiedene Kategorien zusammenzufassen. So könnte man eine neue Variable native-continent bilden, die jeweils Bürger mit europäischer, süd-amerikanischer, afrikanischer, asiatischer, ... Abstammung zusammenfasst:
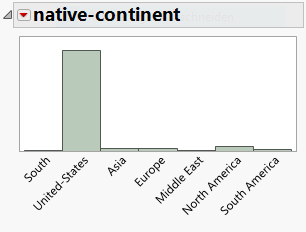
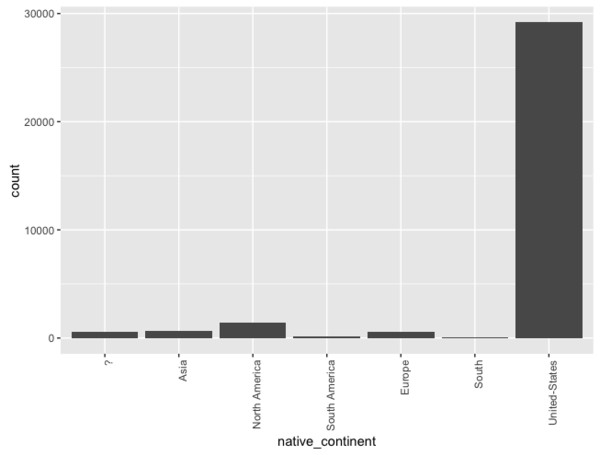
library(plyr)
adult$native_continent = mapvalues(adult$native_country, from=c(" Mexico", " Canada", " Cuba",
" Dominican-Republic", " Puerto-Rico", " El-Salvador",
" Guatemala", " Jamaica", " Haiti", " Nicaragua",
" Outlying-US(Guam-USVI-etc)",
" Philippines", " India", " China", " Japan",
" Taiwan", " Hong", " Cambodia", " Laos", "
Vietnam", " Thailand", "
Germany", " England", " Italy", " Poland", "
Iran", " Portugal", " France", " Greece", "
Ireland", " Yugoslavia", " Hungary", " Scotland",
" Holand-Netherlands", "
Columbia", " Peru", " Ecuador", " Honduras",
" Trinadad&Tobago", " United-States"),
to=c(rep("North America", 11),
rep("Asia", 10),
rep("Europe", 13),
rep("South America", 5),
"United-States" ))
# Überblick: native_continent
ggplot(adult, aes(x=native_continent)) + geom_bar() +
theme(axis.text.x = element_text(angle = 90, hjust = 1))
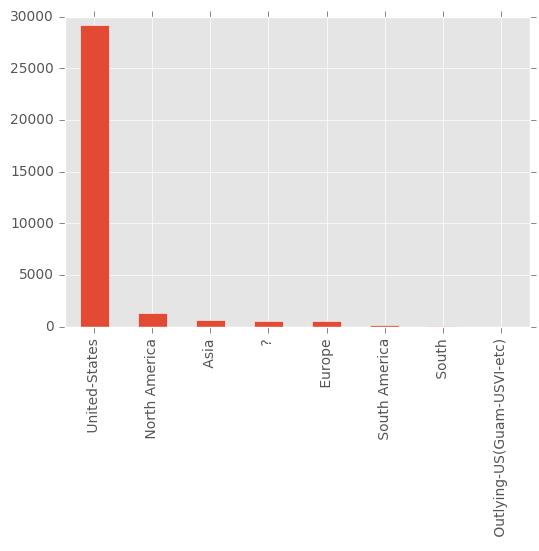
adult['native_continent'] = adult['native_country'].str.replace("Mexico", "North America")
adult['native_continent'] = adult['native_continent'].str.replace("Canada", "North America")
adult['native_continent'] = adult['native_continent'].str.replace("Cuba", "North America")
adult['native_continent'] = adult['native_continent'].str.replace("Dominican-Republic", "North America")
adult['native_continent'] = adult['native_continent'].str.replace("Puerto-Rico", "North America")
adult['native_continent'] = adult['native_continent'].str.replace("El-Salvador", "North America")
adult['native_continent'] = adult['native_continent'].str.replace("Guatemala", "North America")
adult['native_continent'] = adult['native_continent'].str.replace("Jamaica", "North America")
adult['native_continent'] = adult['native_continent'].str.replace("Haiti", "North America")
adult['native_continent'] = adult['native_continent'].str.replace("Nicaragua", "North America")
adult['native_continent'] = adult['native_continent'].str.replace("Outlying-US(Guam-USVI-etc)", "North America")
adult['native_continent'] = adult['native_continent'].str.replace("Philippines", "Asia")
adult['native_continent'] = adult['native_continent'].str.replace("India", "Asia")
adult['native_continent'] = adult['native_continent'].str.replace("China", "Asia")
adult['native_continent'] = adult['native_continent'].str.replace("Japan", "Asia")
adult['native_continent'] = adult['native_continent'].str.replace("Taiwan", "Asia")
adult['native_continent'] = adult['native_continent'].str.replace("Hong", "Asia")
adult['native_continent'] = adult['native_continent'].str.replace("Cambodia", "Asia")
adult['native_continent'] = adult['native_continent'].str.replace("Laos", "Asia")
adult['native_continent'] = adult['native_continent'].str.replace("Vietnam", "Asia")
adult['native_continent'] = adult['native_continent'].str.replace("Thailand", "Asia")
adult['native_continent'] = adult['native_continent'].str.replace("Germany", "Europe")
adult['native_continent'] = adult['native_continent'].str.replace("England", "Europe")
adult['native_continent'] = adult['native_continent'].str.replace("Italy", "Europe")
adult['native_continent'] = adult['native_continent'].str.replace("Poland", "Europe")
adult['native_continent'] = adult['native_continent'].str.replace("Iran", "Europe")
adult['native_continent'] = adult['native_continent'].str.replace("Portugal", "Europe")
adult['native_continent'] = adult['native_continent'].str.replace("France", "Europe")
adult['native_continent'] = adult['native_continent'].str.replace("Greece", "Europe")
adult['native_continent'] = adult['native_continent'].str.replace("Ireland", "Europe")
adult['native_continent'] = adult['native_continent'].str.replace("Yugoslavia", "Europe")
adult['native_continent'] = adult['native_continent'].str.replace("Hungary", "Europe")
adult['native_continent'] = adult['native_continent'].str.replace("Scotland", "Europe")
adult['native_continent'] = adult['native_continent'].str.replace("Holand-Netherlands", "Europe")
adult['native_continent'] = adult['native_continent'].str.replace("Columbia", "South America")
adult['native_continent'] = adult['native_continent'].str.replace("Peru", "South America")
adult['native_continent'] = adult['native_continent'].str.replace("Ecuador", "South America")
adult['native_continent'] = adult['native_continent'].str.replace("Honduras", "South America")
adult['native_continent'] = adult['native_continent'].str.replace("Trinadad&Tobago", "South America")
adult['native_continent'].value_counts().plot(kind='bar')
Zusammenfassung
Dieses Mal haben wir uns einen Überblick über einige Aspekte verschafft, auf die man bei der Explorativen Datenanalyse oft achtet:
- Gibt es Hinweise auf falsch kodierte Daten?
Häufig werden fehlende Werte mit 0, ?, 'unbekannt' oder 'other' kodiert. - Gibt es ungewöhnliche Häufungen bzw. Ausreißer in den Daten?
Erinnern Sie sich an die mehreren Fälle der Variable capital_gain mit genau dem Wert 99.999. In solchen Situationen ist es geschickt noch einmal nachzuforschen, wie die Daten erhoben wurden. - Wie nützlich kann eine Variable für das zu lösende Problem sein?
Die Variable native-nation zeigt fast nur US-Amerikaner. Es ist fraglich, ob die Variable großen Nutzen hat, da die anderen Nationalität nur sehr selten auftreten. So gesehen ist der Datensatz nicht sehr repräsentativ.
Wer sich für dieses Thema interessiert, dem sei der Blogeintrag Data Exploration with Python von Tony Ojeda ans Herz gelegt. Dort wird noch ausführlicher und systematischer auf dieses Thema eingegangen.
Literatur
- Lichman, M. (2013). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
- Ojeda, Tony (2016): Data Exploration with Python
[Blogpost: link, last checked: 13.01.2017]

Author: Sebastian Hoffmeister