


Seit ihrer ersten Veröffentlichung im Jahr 2011 [1] haben sich Defintive Screening Designs (DSDs) zu einem Standard-Werkzeug in der statistischen Versuchsplanung gemausert. Während die statistischen Qualitäten schon früh diskutiert wurden, gibt es bisher nur wenig Material, welches sich mit der Auswertung dieser Art von Versuchsplänen beschäftigt [2].
Definitive Screening Design - Schematisch
In diesem Blogeintrag beschäftigen wir uns mit der von B. Jones vorgeschlagenen Auswertemthodik und untersuchen Sie insbesondere in Hinblick auf ihre Power.
Das Problem super-saturierter Designs
Beginnen wir mit der besonderen Herausforderung bei der Auswertung super-saturierter Designs. Das wird die Frage beantworten, warum überhaupt besondere Auswerteverfahren notwendig sind um z.B. Definitive Screenings auszuwerten.
Beispiel
Es soll der Einfluss von 6 Faktoren auf einen Response mittels eines DSDs mit 17 Versuchen untersucht werden. Eine schöne Eigenschaft von DSDs ist nun, dass die Haupteffekte unabhängig von Zweifachwechselwirkungen und quadratischen Effekten geschätzt werden können. Darüber hinaus sind Zweifachwechselwirkungen und quadratische Effekte nur partiell miteinander vermengt. D.h. mithilfe dieser Designs sollten wir in der Lage sein auch etwas über Effekte 2. Ordnung zu lernen.
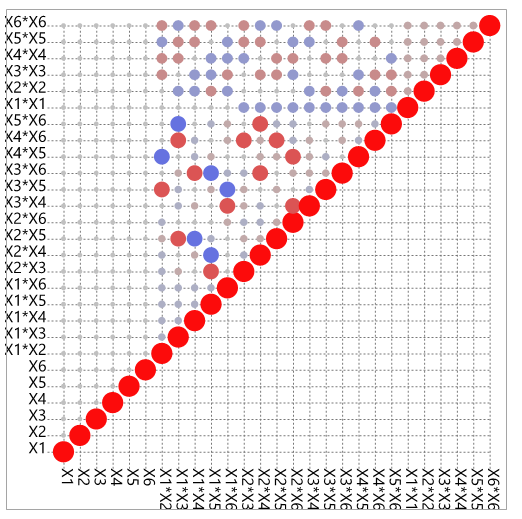
Farbmatrix der Korrelationen in einem DSD
In der Farbmatrix der Korrelationen kann man diese Eigenschaft noch einmal gut ablesen. Die Größe der Kreise stellt die Korrelation zwischen verschiedenen Modelleffekten dar. Es gibt also einige partielle Korrelationen zwischen Zweifachwechselwirkungen und quadratischen Termen. Diese sind aber relativ klein. Deshalb sollten wir in der Lage sein Aussagen über Haupteffekte (Main Effects: ME), Zweifachwechselwirkungen (2-Factor-Interactions: 2FI) und quadratische Effekte (quadratic Effects: QE) machen können.
Was ist nun das Problem? Die Farbmatrix der Korrelationen misst gewissermaßen wie gut die Verteilung der Experimente im Raum ist um Aussagen über die einzelnen Modelleffekte zu machen. Dabei wird allerdings nicht die berücksichtigt ob überhaupt genug Daten für die Schätzung des Modells vorliegen.
Bei der Berechnung eines Regressionsmodells benötigen wir mindestens einen Datenpunkt für die Schätzung eines Steigungskoeffizienten. In unserem Fall sieht das komplette Modell folgendermaßen aus:

Daraus ergibt sich, dass wir insgesamt 1+6+15+6 = 28 Datenpunkte bräuchten um das vollständige Modell berechnen zu können. Noch nicht berücksichtigt wurde dabei, dass dann noch keine p-Werte bestimmt werden können, weil keine Residualstreuung berechnet werden kann. Da in unserem Fall aber nur 17 Datenpunkte vorliegen ergibt sich folgendes Problem:
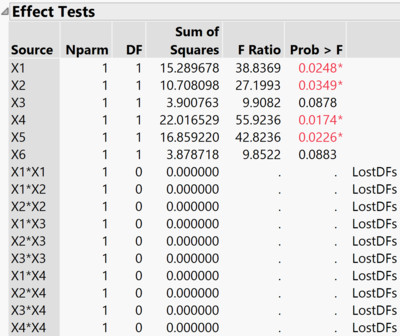
JMP Output: Berechnung eines übersaturierten Modells via "Fit Model"
Da nicht genug Datenpunkte vorliegen, kann JMP nur für einen Teil der Parameter Steigungen und Tests berechnet. Die restlichen Parameter werden aus Mangel an Freiheitsgraden auf 0 gesetzt.
Auswerte-Strategie
Die von B. Jones [2] vorgeschlagene Auswertemethodik benutzt einen zweistufigen Ansatz um dieses Problem zu umgehen.
- Im ersten Schritt wird eine Regressionsanalyse allein für die Haupteffekte des Modells berechnet.
- Im zweiten Schritt wird eine Regression mit den Residuen der Regression des ersten Schrittes als Zielgröße berechnet. Einflussfaktoren sind alle 2FIs und QE, die sich aus den aktiven Effekten des ersten Schrittes ergeben.
- Die aktiven Effekte aus den beiden Schritten werden zuletzt zu einem finalen Modell kombiniert.
Schauen wir uns das Verfahren etwas genauer an: Der erste Schritt zielt darauf ab die wichtigen Haupteffekte zu identifizieren. Jedes DSD hat mehr als genug Daten um die Haupteffekte sauber zu schätzen. Soweit passiert also nicht viel neues außer dass bisher 2FIs und QEs ignoriert werden.
Im zweiten Schritt werden dann die Residuen der ersten Regression als Zielgröße verwendet. Die Idee dahinter ist es, dass nur die Streuung in den Daten modelliert werden soll, die nicht bereits im ersten Modell erfasst wurde. Die gleiche Idee wird z.B. auch bei der Konstruktion von Leverage-Plots verwendet [3], [4].
Allein das Aufteilen in 2 separate Schritte reicht aber oft nicht. Im vorliegenden Beispiel bleiben ja immer noch 15+6 = 21 Modelleffekte bei weiterhin 17 Daten. Hier bedient sich B. Jones der gängigen Argumentation, dass in der Regel die zugehörigen Haupteffekte signfikant sind, wenn sie ebenfalls in einer Wechselwirkung vorkommen. Es werden also nur die Wechselwirkungen (und quadratischen Effekte) untersucht, die sich aus den signifikanten Haupteffekten des ersten Modells ergeben.
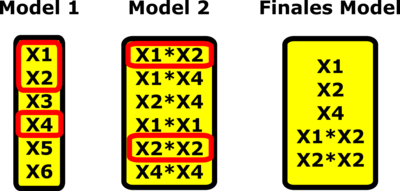
Schematisches Beispiel: Modellwahl in 3 Schritten
Obige Darstellung veranschaulicht das Vorgehen an einem Beispiel:
- Von allen Haupteffekten erweisen sich X1, X2 und X4 als signifikant.
- Im zweiten Schritt wird ein Modell für die resultierenden 2FIs X1*X2, X1*X4, X2*X4 sowie für die QE X1*X1, X2*X2 und X4*X4 geschätzt.
- Das finale Modell ergibt sich aus den signifikanten Effekten der Modelle 1 und 2.
Simulationsstudie als Poweranalyse
Um die Effizienz des Verfahrens zu testen wurde eine simulationsbasierte Power-Analyse durchgeführt. Dazu wurden für ein gegebenes DSD (6 stetige Faktoren, 17 Versuche) Werte für die Zielgröße simuliert. Dabei wurde das folgende Modell verwendet:
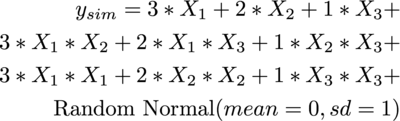
In 10.000 Simulationen wurde untersucht, wie oft mit dem besprochenen Algorithmus die wahren Effekte mit den unterschiedlichen Effektstärken (3, 2 und 1) wiedergefunden werden.
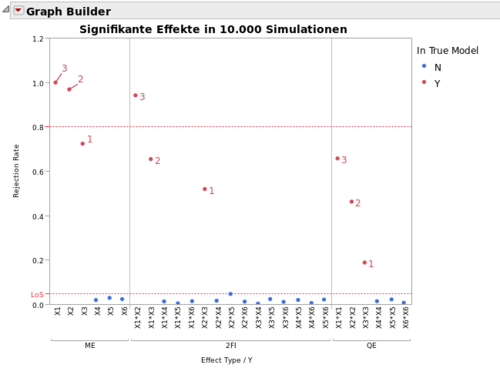
Simulationsergebnisse der Powerstudie
Obige Grafik visualisiert die Resultate der Simulationsstudie. Man erkennt, dass die Haupteffekte mit einem Effekt von 2 bzw. 3 Standardabweichungen in so gut wie allen Fällen erkannt wurden (Power = 100%). Nur Haupteffekte mit einem Effekt von einer Standardabweichung wiesen eine Power von etwas unter 80% auf.
Starke 2FIs können scheinbar auch gut erkannt werden, während die Power hier mit abnehmender Effektgröße schneller sinkt.
Die Fähigkeit quadratische Effekte zu entdecken ist generel etwas geringer und hängt dramatisch von der Effektgröße ab.
Der Leser sollte sich allerdings bewußt machen, dass andere Arten von Screening-Designs überhaupt keine Möglichkeit liefern quadratische Effekte zu identifizieren. Außerdem muss klar sein, dass die Power eines realen Designs stark von dem tatsächlichen Signal-Rausch-Verhältnissen sowie auch von der Anzahl der aktiven Effekte abhängt. Obige Grafik kann also nur als ein spezielles Szenario betrachtet werden und ist nicht komplett verallgemeinerbar.
Bewertung
Das vorgeschlagene Verfahren erweist sich in Hinblick auf die Power verschiedenen alternativen Verfahren als überlegen (siehe [2]). In einigen oberflächlichen simulationsbasierten Vergleichen mit AICc basierter Foreward-Regression, LASSO und Elastic Net erwies sich das vorgeschlagene Verfahren jeweils als besser. Hier sind allerdings noch weitere Studien erforderlich.
Zwei Punkte sollen noch explizit erwähnt werden:
- Das Verfahren stützt sich auf die Annahme, dass alle Haupteffekte die in einer aktiven Wechselwirkung vorkommen auch selbst aktiv sind. Diese Annahme ist in der Praxis zwar häufig, aber nicht immer erfüllt.
Sofern genug Freiheitsgerade vorhanden sind könnte man das Verfahren so erweitern, dass im zweiten Schritt alle 2FIs in denen mindestens ein aktiver Effekt aus dem ersten Modell vorkommt, berücksichtigt werden. Freilich ergeben sich dadurch neue mögliche Probleme, z.B. dass das finale Modell zu groß wird um es mit den vorhandenen Daten noch plausibel schätzen zu können. - Ferner sollte der Anwender sich bewußt sein, dass die vorgestellte Auswerteroutine besonders davon profitiert, dass in DSDs keine Korrelationen zwischen ME und 2FIs/Qes vorliegen. Die zweistufige Herangehensweise macht keinen Sinn für übersaturierte Designs in denen Aliasing zwischen ME und 2FIs vorliegen (Teilfaktorielle Pläne).
Trotz dieser Einschränkung erscheint die beschriebene Methodik der beste systematische Auswerteansatz für DSDs zu sein.
Auch wenn diese Auswertungen sehr einfach per Hand durchgeführt werden kann ist es deutlich komfortabler die entsprechende Route in JMP 13 zu verwenden [5].
Literatur
- B. Jones, C.J. Nachtsheim: A Class of Three-Level Designs for Definitive Screening in the Presence of Second-Order Effects
- B. Jones: Analysis of Definitive Screening Designs bzw. mit
B. Heinen in deutsch: Auswertung von Definitive Screening Designs - W. Levin: Applied Statistical Essentials (Episode: 3 and 4)
- JMP Online Help: Leverage Plots
- JMP Online Help: The Fit Definitive Screening Plattform

Author: Sebastian Hoffmeister