

Stata SE

Die besondere Stärke von Stata liegt in der Auswertung von zeitbasierten Daten. Angefangen von einfachen Zeitreihenmodellen (ARIMA) über die multivariate Pendants (VAR/VEC) stellen Sie auch Modelle zur Beschreibung von Volatilitäten (GARCH) auf. Mithilfe von Kaplan-Meier-Schätzern modellieren Sie Lebensdauern oder nutzen gemischte Modelle um Zusammenhänge in Paneldaten zu untersuchen. Abgerundet wird Stata durch eine mächtige Programmiersprache zur Automatisierung und Entwicklung neuer Methoden.
Breites Spektrum an statistischen Methoden
Stata gibt Ihnen aber auch alle Möglichkeiten der klassischen Statistik und noch vieles mehr. So können Sie mit Stata deskriptive Statistiken erstellen, gängige Hypothesentests (Mittelwertvergleiche, Tests auf Normalverteilung - jeweils nonparametrisch und parametrisch) berechnen oder Ihre Daten mit wissenschaftlichen Graphiken visualisieren.
Stata als umfangreiches statistisches Softwarepaket eignet sich vor allem für den Einsatz in Forschung und Entwicklung. Das breite Spektrum an hochwertigen statistischen Methoden aller Disziplinen dient einem großen Nutzerkreis. Insbesondere Forscher aus den Bereichen Soziologie, Ökonomie, Politik- und Sozialwissenschaft sowie Epidemiologie und anderen medizinischen Fachgebieten finden in Stata die benötigten Verfahren der Statistik.
Egal ob Sie Student oder Senior Researcher sind, es gibt immer die passende Stata Version für jede Komplexität und Größe des Datensatzes: Stata/BE, Stata/SE und Stata/MP
Argumente für Stata:
- Vor allem einsetzbar in Forschung und Entwicklung
- Stata besitzt eine umfangreiche Palette an statistischen und graphischen Funktionen und erstellt hochwertige Diagramme
- Stata ist eine allgemeine Statistiksoftware mit umfassende Funktionalität
- Stata ist flexibel und umfangreich bei der Auswertung von Zeitreihendaten
- Stata hat eine leicht erlernbare und trotzdem mächtige Programmiersprache
Dies könnte Sie auch interessieren
![]()
Limdep
![]()

NLOGIT (inkl. Limdep)
![]()
Stata MP
![]()
Stata/SE
Mit Stata erhalten Sie ein umfangreiches statistisches Softwarepaket für den Einsatz in Forschung und Entwicklung. Stata bietet ein breites Spektrum umfangreicher und hochwertiger statistischer Methoden aller Disziplinen. Insbesondere Forscher aus den Bereichen Soziologie, Ökonomie, Politik- und Sozialwissenschaft sowie Epidemiologie und aus anderen medizinischen Fachgebieten finden die für sie spezifischen Ansätze in Stata realisiert (Survival Analysis, Panel-Data, ...)
Stata ist in allen Betriebssystemwelten zuhause. Stata kann in Windows-, Macintosh- und Unix-Umgebungen genutzt werden.
Stata steht in 3 Editionen zur Verfügung
Ob für erfahrene Statistiker oder Erstsemester-Studenten - Stata gibt es für jeden Anwender in der passenden Edition
- Stata/MP: die größte und schnellste Stata-Version (Dual-core und Multicore-Computer)
- Stata/SE: Stata für sehr große Datendateien
- Stata/BE: Stata Standardversion
Stata / MP ist die schnellste und größte Version von Stata. Praktisch jeder aktuelle Computer kann das erweiterte Multiprocessing von Stata / MP nutzen. Dazu gehören die Intel i3-, i5-, i7-, i9-, Xeon- und Celeron- sowie AMD-Multi-Core-Chips. Auf Dual-Core-Chips läuft Stata / MP bei den zeitaufwendigen Schätzbefehlen 40% schneller. Mit mehr als zwei Kernen oder Prozessoren ist Stata / MP noch schneller. Sie können eine Stata / MP-Lizenz für die Anzahl der Kerne auf Ihrem Computer erwerben (maximal 64). Wenn Ihr Computer beispielsweise über acht Kerne verfügt, können Sie eine Stata / MP-Lizenz für acht, vier oder zwei Kerne erwerben.
Stata / MP kann auch mehr Daten analysieren als jeder andere Version von Stata. Stata / MP kann 10 bis 20 Milliarden Beobachtungen mit den derzeit größten Computern analysieren und ist bereit, bis zu 1 Billion Beobachtungen zu analysieren, sobald die Computerhardware aufholt.
Stata / SE und Stata / BE unterscheiden sich nur in der Datensatzgröße. Stata / SE und Stata / MP können Modelle mit unabhängigeren Variablen als Stata / BE (bis zu 10.998) anpassen. Stata / SE kann bis zu 2 Milliarden Beobachtungen analysieren.
Stata / BE erlaubt Datensätze mit bis zu 2048 Variablen und 2 Milliarden Beobachtungen. Stata / BE kann höchstens 798 unabhängige Variablen in einem Modell bedienen.
Numerics by Stata kann jede der oben aufgeführten Datengrößen in einer eingebetteten Umgebung unterstützen.
Alle oben genannten Varianten haben den gleichen vollständigen Funktionsumfang und enthalten eine PDF-Dokumentation.
| Product features | Stata/BE | Stata/SE | Stata/MP |
| Maximum number of variables | 2,048 | 32,767 | 120 |
| Maximum number of observations | 2.14 billion | 2.14 billion | Up to 20 billion |
| Maximum number of independent variables | 798 | 10,998 | 10,998 |
| Multicore support (Time to run logistic regression with 5 million obs and 10 covariates ) | 1-core/ 10.0 sec | 1-core/ 10.0 sec | 2- core (5.0 sec), 4-core (2,6 sec), 4+ core (even faster) |
| Complete suite of statistical features | Yes! | Yes! | Yes! |
| Publication-quality graphics | Yes! | Yes! | Yes! |
| Matrix programming language | Yes! | Yes! | Yes! |
| Complete PDF documentation | Yes! | Yes! | Yes! |
| Exceptional technical support | Yes! | Yes! | Yes! |
| Includes within-release updates | Yes! | Yes! | Yes! |
| 64-bit version available | Yes! | Yes! | Yes! |
| Windows, macOS, and Linux | Yes! | Yes! | Yes! |
| Memory requirements | 1 GB | 2 GB | 4 GB |
| Disk space requirements | 1 GB | 1 GB | 1 GB |
* Die Anzahl der Beobachtungen ist nur durch die Größe des Arbeitsspeichers begrenzt.
Komplexe Funktionen mit Mata vereinfachen
Die eigene Programmiersprache Mata ist leicht erlernbar, denn sie ist einfach und kohärent. Zusätzlich hilft Ihnen die umfangreiche Palette an statistischen und graphischen Funktionen, sich auf die Analyse Ihrer Daten zu konzentrieren ohne programmieren zu müssen. Sollte aber mal eine Funktion fehlen, so ist es mit Hilfe der Programmiersprache möglich, die bestehende Funktion zu bearbeiten oder eine neue zu erstellen. Die Rechnergeschwindigkeit von Stata passt sich den jeweiligen Berechnungen (groß oder klein) an.
Sinnvolle Datenverwaltungsfunktionen
Die Datenverwaltungsfunktionen helfen Ihnen die Gesamtheit der Daten zu verändern. Das Zusammenführen von Datensätzen, die Schaffung oder Berechnung neuer Variablen ist mit wenig Aufwand möglich. Das tabellarische Interface unter Windows bzw. Mac vereinfacht die Aufgabenbearbeitung nochmals.
Mit Stata hochwertige Diagramme erstellen und individualisieren
Mit Stata erstellen Sie qualitativ hochwertige Diagramme für Publikationen und interne Dokumente. Sie können jederzeit zwischen vordefinierten oder selbst eingestellten Diagrammtypen wählen. Mit dem integrierten Grafik-Editor können Sie auch die Diagramme individualisieren. Mit den selbst geschriebenen Skripten lassen sich zahlreiche individuelle Grafiken erzeugen und exportieren.
Weitere Informationen
Demoversion der Software Stata
Auf der Seite des Herstellers Stata Corp. können Sie sich für eine kostenlose 30-tägige Demoversion registrieren. Die Demoversion stellt Ihnen alle Funktionen von Stata zur Verfügung. Zur Registrierung besuchen Sie bitte die Herstellerseite: http://www.stata.com/customer-service/evaluate-stata/
Systemanforderung
Stata for Windows
- Windows 10*
- Windows 8*
- Windows Server 2019, 2016, 2012*
* 64-bit for x86-64 made by Intel® and AMD
Stata for Mac
- Mac with Apple Silicon or 64-bit Intel processor
- macOS 11.12 (Sierra) or newer for Macs with Intel processors and macOS 11.0 (Big Sur) or newer for Macs with Apple Silicon
Stata for Linux
- 64-bit (x86-64)
- For xstata, you need to have GTK 2.24 installed
Hardware-requirements
- Minimum of 1 GB of RAM für IC, 2 GB RAM für SE, 4 GB RAM für MP
- Minimum of 2 GB of disk space
- Stata for Unix requires a video card that can display thousands of colors or more (16-bit or 24-bit color)
Neue wichtige Features in STATA :
Neue wichtige Features in STATA :
Tables:
Users have been asking us for better tables. Here they are. You can easily create tables that compare regression results or summary statistics, you can create styles and apply them to any table you build, and you can export your tables to MS Word®, PDF, HTML, LaTeX, MS Excel®, or Markdown and include them in reports. The table command is revamped. The new collect prefix collects as many results from as many commands as you want, builds tables, exports them to many formats, and more. You can also point-and-click to create tables using the new Tables Builder.
https://www.stata.com/new-in-stata/tables
Bayesian econometrics:
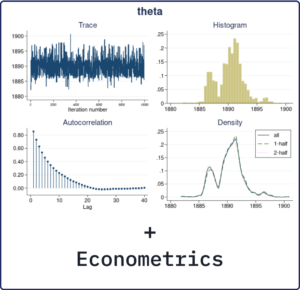
Stata does econometrics. And Stata does Bayesian statistics. Stata 17 now does Bayesian econometrics. Want to use probabilistic statements to answer economic questions, for example, Are those who participate in a job-training program more likely to stay employed for the next five years? Want to incorporate prior knowledge of an economic process? Stata’s new Bayesian econometrics features can help. Fit many Bayesian models such as cross-sectional, panel-data, multilevel, and time-series models. Compare models using Bayes factors. Obtain predictions and forecasts. And more!
One of the appeals for using Bayesian methods in econometric modeling is to incorporate the external information about model parameters often available in practice. This information may come from historical data, or it may come naturally from the knowledge of an economic process. Either way, a Bayesian approach allows us to combine that external information with what we observe in the current data to form a more realistic view of the economic process of interest.
Stata 17 offers several new features in the area of Bayesian econometrics:
Bayesian VAR models
Bayesian IRF and FEVD analysis
Bayesian dynamic forecasting
Bayesian longitudinal/panel-data models
Bayesian linear and nonlinear DSGE models
Faster STATA:
Stata values accuracy and it values speed. There is often a tradeoff between the two, but Stata strives to give users the best of both worlds. In Stata 17, we updated the algorithms behind sort and collapse to make these commands faster. We also attained speed improvements for some estimation commands such as mixed, which fits multilevel mixed-effects models.
https://www.stata.com/new-in-stata/faster-stata-speed-improvements
Difference-in-differences (DID) and DDD models:
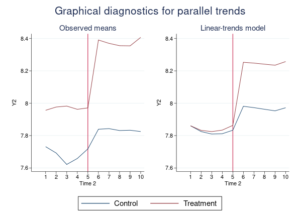 New estimation commands didregress and xtdidregress fit difference-in-differences (DID) and difference-in-difference-in-differences or triple-differences (DDD) models with repeated-measures data. didregress works with repeated-cross-sectional data, and xtdidregress works with longitudinal/panel data.
New estimation commands didregress and xtdidregress fit difference-in-differences (DID) and difference-in-difference-in-differences or triple-differences (DDD) models with repeated-measures data. didregress works with repeated-cross-sectional data, and xtdidregress works with longitudinal/panel data.
DID and DDD models are used to estimate the average treatment effect on the treated (ATET) with repeated-measures data. A treatment effect can be an effect of a drug regimen on blood pressure or an effect of a training program on employment. Unlike with the standard cross-sectional analysis, available with the existing teffects command, DID analysis controls for group and time effects when estimating the ATET, where groups identify repeated measures. DDD analysis controls for additional group effects and their interactions with time—you can specify up to three group variables or two group variables and a time variable.
https://www.stata.com/new-in-stata/difference-in-differences-DID-DDD
Interval-censored Cox model:
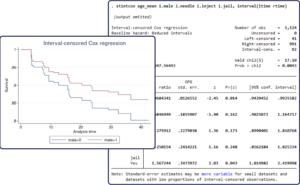
A semiparametric Cox proportional hazards regression model is commonly used to analyze uncensored and right-censored event-time data. The new estimation command stintcox fits the Cox model to interval-censored event-time data.
Interval-censoring occurs when the time to an event of interest, such as recurrence of cancer, is not directly observed but is known to lie within an interval. For example, the recurrence of cancer can be detected between periodic examinations, but the exact time of recurrence cannot be observed. We know only that cancer recurred sometime between the previous and current examinations. Ignoring interval-censoring may lead to incorrect (biased) results.
Semiparametric estimation, when the baseline hazard function is left completely unspecified, of interval-censored event-time data is challenging because none of the event times are observed exactly. As such, „semiparametric“ modeling of these data often resorted to using spline methods or piecewise-exponential models for the baseline hazard function. Genuine semiparametric modeling of interval-censored event-time data was not available until recent methodological advances, which are implemented in the stintcox command.
https://www.stata.com/new-in-stata/interval-censored-cox-model
The bayes prefix now supports the var command to fit Bayesian vector autoregressive (VAR) models.
VAR models study relationships between multiple time series by including lags of outcome variables as model predictors. These models are known to have many parameters: with K outcome variables and p lags, there are at least p(K^2+\nn1) parameters. Reliable estimation of the model parameters can be challenging, especially with small datasets.
Bayesian VAR models overcome these challenges by incorporating prior information about model parameters to stabilize parameter estimation.
Bayesian multilevel models nonlinear, joint, SEM-like and more:
 You can fit breadth of Bayesian multilevel models with the new elegant random-effects syntax of the bayesmh command. You can fit univariate linear and nonlinear multilevel models more easily. And you can now fit multivariate linear and nonlinear multilevel models! Think of growth linear and nonlinear multilevel models, joint longitudinal and survival-time models, SEM-type models, and more.
You can fit breadth of Bayesian multilevel models with the new elegant random-effects syntax of the bayesmh command. You can fit univariate linear and nonlinear multilevel models more easily. And you can now fit multivariate linear and nonlinear multilevel models! Think of growth linear and nonlinear multilevel models, joint longitudinal and survival-time models, SEM-type models, and more.
https://www.stata.com/new-in-stata/bayesian-multilevel-modeling
Treatmen effects lasso estimation:

You use teffects to estimate treatment effects. You use lasso to control for many covariates. (And when we say many, we mean hundreds, thousands, or more!) You can now use telasso to estimate treatment effects and control for many covariates.
https://www.stata.com/new-in-stata/causal-inference-treatment-effects-lasso
Galbraith plot:
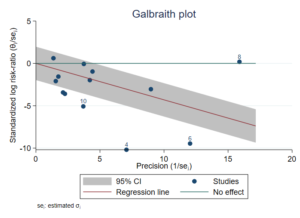
The new command meta galbraithplot produces Galbraith plots for a meta-analysis. These plots are useful for assessing heterogeneity of the studies and for detecting potential outliers. They are also used as an alternative to forest plots for summarizing meta-analysis results when there are many studies.
Nonparametric tests for trend:
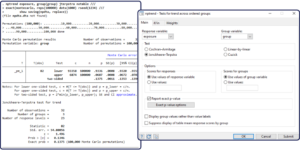
The nptrend command now supports four tests for trend across ordered groups. You can choose between the Cochran–Armitage test, the Jonckheere–Terpstra test, the linear-by-linear trend test, and the Cuzick test using ranks. The first three tests are new, and the fourth test was performed by nptrend previously.
https://www.stata.com/new-in-stata/nonparametric-trend-tests
Stata 17 for Mac is available as a universal application that will run natively on both Macs with Apple Silicon and Macs with Intel processors. Macs with Apple Silicon include the new MacBook Air, MacBook Pro, and Mac mini, all with M1 processors. The M1 chip promises greater performance and greater power efficiency. This is noteworthy to our Stata-for-Mac users, many of whom use Mac laptops.
Although this first set of M1 Macs is considered to be an entry-level set, we have found that M1 Macs natively running Stata outperform Intel Macs by 30–35%. They even greatly outperform or perform as well as Intel Macs that cost more than twice as much! And for users who insist on only Apple-Silicon-native software on their Apple Silicon Macs, you will be happy to know that no part of Stata 17, from the installer to the application itself, requires the use of Rosetta 2.
Stata functions the same way whether you are running Stata natively on an M1 Mac or on an Intel Mac, and no special license is required for the M1 Mac. Intel Mac users should note that we will continue to support and release new versions of Stata for Macs with Intel processors for years to come.
https://www.stata.com/new-in-stata/apple-silicon
Pystata:
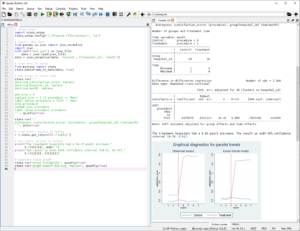
Stata 17 introduces a concept we call PyStata. PyStata is a term that encompasses all the ways Stata and Python can interact.
Stata 16 featured the ability to call Python code from Stata. Stata 17 greatly expands on this by allowing you to invoke Stata from a stand-alone Python environment via a new pystata Python package.
You can access Stata and Mata conveniently in an IPython kernel-based environment (for example, Jupyter Notebook and console and Jupyter Lab and console); in other environments that support the IPython kernel (for example, Spyder IDE and PyCharm IDE); or when accessing Python from a command line (for example, Windows Command Prompt, macOS terminal, Unix terminal, and Python’s IDLE).
https://www.stata.com/new-in-stata/pystata
und sehr viele Features mehr......
Sie finden weitere Informationen zu den Stata News auf folgendem Link:
Lasso-based machine learning
Lasso ist eine maschinelle Lerntechnik, die zur Modellauswahl, Vorhersage und Inferenz verwendet wird.
Der neue -lasso-Befehl wählt abweichungsbasierte „optimale“ Prädiktoren für kontinuierliche, binäre und Häufigkeits-Ergebnisse aus.
Wenn Sie beispielsweise
. lasso linear y x1-x500
eingeben, wählt Lasso eine Teilmenge der angegebenen Kovariaten aus; z. B. x2, x10, x11 und x21. Mit dem standard -predict-Befehl erhalten Sie anschließend Vorhersagen von y.
Sollten Sie es vorziehen, Variablen mittels elastischer Netze oder des Quadratwurzel basierter Methoden auszuwählen, können Sie die Befehle -elasticnet- oder -sqrtlasso- in gleicher Weise verwenden.
Manchmal ist die Variablenauswahl oder die Vorhersage bereits das Endziel von Lasso. Andere Male steht jedoch das Schätzen und Testen von Koeffizienten im Mittelpunkt. Hierfür stehen Ihnen in Stata 16 elf weitere Befehle mit denen Sie Koeffizienten, Standardfehler und Konfidenzintervalle schätzen sowie Tests für interessierende Variablen bei Verwendung von Lasso-Methoden durchführen können. Die Befehle sind
dsregress, dslogit, dspoisson, poregress, pologit, popoisson, poivpoisson, xporegress, xpologit,
xpopoisson und xpoivregress.
Die -ds-Befehle führen ein Lasso mit doppelter Auswahl durch, mit den Befehlen -po- wird ein Partialing-Out-Lasso ausgeführt. Die -xpo-Befehle führen schließlich ein Cross-Fit-Partialing-Out-Lasso durch. Dies tun sie für Modelle mit kontinuierlichen, binären und Zähldaten. In Modellen für kontinuierliche abhängige Variablen können sie sogar endogene Kovariaten berücksichtigen.
Während viele der neueren Lasso-Methoden insbesondere in der Ökonometrie entwickelt werden, erfreuen sie sich in allen Disziplinen wachsender Beliebtheit, da sie auch im Bereich des maschinellen Lernens Möglichkeiten des formalen Testens und der inhaltlichen Interpretation von interessierenden Variablen bieten. Erfahren Sie im neuen Lasso-Referenzhandbuch auf anschauliche Weise alles über die Lasso-Funktionen in Stata 16.
Python integration
In Stata können Sie Python-Code in Stata einbetten und ausführen. Mit dem neuen -python-Befehl können Sie Python einfach aus Stata heraus aufrufen und die Python-Ergebnisse anschließend in Stata ausgeben. Sie können Python sowohl interaktiv über das Kommandofenster als auch über do- bzw. ado-Files aufrufen, um die umfangreichen Funktionen von Python zu nutzen. Ebenso können sie auch Python-Skriptdateien (.py) direkt über Stata ausführen. Für die nahtlose Integration steht Ihnen darüber hinaus das Stata Function Interface (sfi) Python-Modul zur Verfügung. Dieses Modul schafft die bidirektionale Verbindung zwischen Stata und Python und ermöglicht so direkten Zugriff auf die aktuell geöffneten Datensätze (siehe unten), Frames, Makros, Skalare, Matrizen, Wertelabels, Merkmale, globale Mata-Matrizen und mehr. All dies bedeutet, dass Sie jetzt jedes Python-Paket direkt in Stata verwenden können. Mit Matplotlib können Sie beispielsweise dreidimensionale Grafiken erstellen. Oder Sie verwenden NumPy für numerische Berechnungen. Mit Scrapy können Sie Daten direkt aus dem Web sammeln und in Stata verwenden. Und über TensorFlow sowie scikit-learn können Sie zusätzliche Verfahren maschinellen Lernens wie neuronale Netze oder Vektormaschinen verwenden. Und vieles mehr. Um die volle Power dieser neuen Möglichkeiten auszuschöpfen, beinhaltet Statas Do-File-Editor schließlich auch Syntaxhervorhebung für Python. Insgesamt kommen somit nicht nur fortgeschrittene Programmierer in den Genuss der Vorteile der neuen Python-Integration, sondern werden noch viel mehr Benutzer aller Disziplinen über die Verfügbarkeit von Python in Stata begeistert sein.
Import data from SAS and SPSS
Mit den neuen Befehlen -import sas- und -import spss- in Stata 16 können Sie nun auch direkt Daten im SAS- (.sas7bdat) und SPSS-Format (.sav) verwenden. Visuelle Dialoge erleichtern Ihnen den Import mit einer Vorschau der Daten sowie bei Bedarf auch das Auswählen einer Teilmenge von Variablen und Beobachtungen.
Darüber hinaus können Sie mit den neuen Befehlen -import sasxport8- und -export sasxport8- SAS XPORT-Transportdateien nun auch in der Version 8 direkt mit Stata verwenden.
Choice models
In Stata führen wir eine neue, einheitliche Suite von Befehlen für die Auswahlmodellierung ein. Dafür haben wir neue Befehle für die deskriptive Statistik von Auswahldaten ergänzt. Darüber hinaus haben wir vorhandene Befehle zur Schätzung von Auswahlmodellen vereinheitlicht und verbessert. Wir haben sogar einen neues Verfahren zum Schätzen von Mixed-Logit-Modellen für Paneldaten hinzugefügt. Und wir dokumentieren sie gemeinsam im neuen Choice Models Reference Manual. Und das Beste daran: -margins- funktioniert jetzt auch nach der Schätzung von Choice-Modellen. Das bedeutet, dass Sie Ihre Ergebnisse jetzt auf einfache Weise interpretieren können. Während die in der Auswahlmodellierung geschätzten Koeffizienten häufig kaum interpretierbar sind, können Sie mit -margins- auf Grundlage Ihrer Ergebnisse sehr spezifische Fragen stellen und beantworten.
New in Bayesian analysis—Multiple chains, predictions, and more
Mehrere Ketten:Bayesianische Inferenz basierend auf einer MCMC (Markov chain Monte Carlo) Stichprobe ist nur gültig, wenn die Markov-Kette konvergiert hat. Eine Möglichkeit, diese Konvergenz zu bewerten, besteht darin, mehrere Ketten zu simulieren und zu vergleichen. Mit der neuen Option -nchains ()- können Sie dies sowohl mit dem -bayes:-Prefix als auch mit dem Befehl -bayesmh- durchführen.Geben Sie beispielsweise den Befehl
. bayes, nchains(4): regress y x1 x2
ein werden vier unabhängige Ketten simuliert. Die Ketten werden automatisch kombiniert, um ein genaueres Endergebnis zu erzielen. Vor der Ergebnisinterpretation können Sie die Ketten auch grafisch vergleichen, um die Konvergenz zu bewerten. Oder Sie bewerten die Konvergenz mittels der Gelman-Rubin-Konvergenzdiagnose, die nun von -bayes: regress- und anderen Bayes-Schätzbefehlen bei multiplen Ketten berichtet wird. Wenn Sie daraufhin immer noch Bedenken hinsichtlich Nichtkonvergenz haben, können Sie mit dem Befehl -bayesstats grubin- noch genauer nachforschen und individuelle Gelman-Rubin-Diagnostiken für jeden Parameter Ihres Modells durchführen. Bayes‘sche Vorhersagen:Bayes’sche Vorhersagen sind simulierte Werte aus der posterioren Vorhersageverteilung. Diese Vorhersagen sind nützlich, um die Modellgüte zu überprüfen sowie Beobachtungen außerhalb der Stichprobe vorherzusagen. Nachdem Sie ein Modell mit -bayesmh- geschätzt haben, können Sie nun -bayespredict- verwenden, um diese simulierten Werte oder Funktionen zu berechnen und in einem neuen Datensatz zu speichern. Beispielsweise können Sie Minimum und Maximum der simulierten Werte berechnen. Anschließend können Sie andere postestimation Befehle wie -bayesgraph- verwenden, um Zusammenfassungen der Vorhersagen zu erhalten.Der von -bayespredict- erzeugte Datensatz kann Tausende von simulierten Werten für jede Beobachtung in Ihrem Datensatz enthalten. Mitunter brauchen Sie jedoch nicht alle Einzelwerte. Um stattdessen Zusammenfassungen wie beispielsweise posteriore Mittelwerte oder Mediane zu erhalten, können Sie auch -bayespredict, pmean- oder -bayespredict, pmedian- verwenden. Alternativ könnten Sie an einer Zufallsauswahl der simulierten Werte interessiert sein. Hierzu können Sie beispielsweise -bayesreps, nreps(100)- verwenden, um 100 Replikate zufällig auszuwählen. Und mehr:Schließlich möchten Sie möglicherweise die Anpassungsgüte des Modells unter Verwendung posteriorer prädiktiver p-Werte (auch als PPPs oder Bayes’sche prädiktive p-Werte bezeichnet) bewerten. PPPs messen die Übereinstimmung zwischen den beobachteten und replizierten Daten und können mit dem neuen Befehl -bayesstats ppvalues- berechnet werden.
Manuskripterstellung & Reporting
Mit den Berichtsfunktionen von Stata können Sie Word-, PDF-, Excel- und HTML-Dokumente erstellen, die Stata-Ergebnisse und -Diagramme mit formatiertem Text und Tabellen enthalten. Unabhängig von der Art des von Ihnen erstellten Dokuments können Sie sich auf die integrierten Versionsfunktionen von Stata verlassen, um sicherzustellen, dass Ihre Berichte reproduzierbar sind.
Neue Berichtsfunktionen in Stata:
Mit den Befehlen -dyndoc- und -markdown- erstellen Sie zusätzlich zu den bisherigen HTML-Dokumenten nun auch Word-Dokumente. Dadurch können Sie nun noch einfacher vollständige Stata-Ergebnisse und Grafiken in Markdown-Text einbinden, um benutzerdefinierte Word-Dokumente zu erstellen.
Hierfür bietet der Do-File-Editor jetzt auch Syntaxhervorhebung speziell für Markdown.
Mit dem -putdocx-Befehl können Sie jetzt außerdem auch Kopf- und Fußzeilen inklusive Seitenzahlen einrichten. Darüber hinaus ist es jetzt auch einfacher mit dem Befehl längere Absätze zu schreiben.
Schließlich wandelt der -html2docx-Befehl HTML-Dokumente, einschließlich CSS, in Word-Dokumente um. Der Befehl -docx2pdf- konvertiert Word-Dokumente im Handumdrehen in PDF-Dateien.
Multiple datasets in memory
Sie können jetzt mehrere Datensätze in den Speicher laden. Geben Sie wie gewohnt -use teilnehmer- ein und teilnehmer.dta wird geladen. Geben Sie als Nächstes
. frame create laender
. frame laender: use laender
ein und schon haben Sie zwei Datensätze im Speicher geöffnet. Das gleichzeitige Arbeiten mit mehreren Datensätzen war ein viel gewünschtes Feature unserer Nutzer. Besonders mächtig wird es jedoch durch das einfache Verlinken verbundener Datenstrukturen. Stellen Sie sich beispielsweise vor, dass beide Datensätze die Variable „bundesland“ beinhalten, welche die Bundesländer auf dieselbe Weise identifiziert. Indem Sie einfach
. frlink m:1 bundesland, frame(laender)
eingeben, sind alle Teilnehmenden im default-Frame mit einem Bundesland im laender-Frame verknüpft. Nun können Sie spielend einfach Variablen zwischen Frames kopieren oder mit der Funktion -frval()-direkt auf Werte von Variablen in gelinkten Frames zuzugreifen. Beispielsweise könnten Sie mit dem Befehl:
. generate rel_einkommen = einkommen / frval(laender, median_einkommen)
aus dem individuellen Teilnehmer-Einkommen sowie dem Median des Einkommens im jeweiligen Bundesland direkt eine neue Variable mit dem relativen Einkommen erzeugen. Und das ist erst der Anfang: Während dieses Beispiel lediglich zwei Frames verwendet, können Sie bis zu 100 Frames gleichzeitig laden und zahlreiche Links zwischen den jeweiligen Frames erstellen.
Weitere Features in STATA
Panel-data ERMs
Meta-analysis
Nonparametric series regression
Sample-size analysis for confidence intervals
Nonlinear DSGE models
Multiple-group IRT models
xtheckman
Multiple-dose pharmacokinetic modeling
Heteroskedastic ordered probit models
Graph sizes in printer points, centimeters, and inches
Numerical integration
Linear programming
Stata in Korean
Mac interface now supports Dark Mode and native tabbed windows
Do-file Editor—Autocompletion and more syntax highlighting
Mehr Informationen zu STATA finden Sie hier:
https://www.stata.com/new-in-stata/#new-mata-link
Stata Features
Data management
data transformations, match-merge, ODBC, XML, by-group processing, append files, sort, row–column transposition, labeling, saving results
Basic statistics
summaries, cross-tabulations, correlations, t tests, equality-of-variance tests, tests of proportions, confidence intervals, factor variables
Linear models
regression; bootstrap, jackknife, and robust Huber/White/sandwich variance estimates; instrumental variables; three-stage least squares; constraints; quantile regression; GLS
Multilevel mixed-effects models
generalized linear models;continuous, binary, and count outcomes; two-, three-, and higher-level models; random-intercepts; random-slopes; crossed random effects; BLUPs of effects and fitted values; hierarchical models; residual error structures; support for survey data in linear models
Binary, count, and discrete outcomes
logistic, probit, tobit; Poisson and negative binomial; conditional, multinomial, nested, ordered, rank-ordered, and stereotype logistic; multinomial probit; zero-inflated and left-truncated count models; selection models; marginal effects
Longitudinal data/panel data
random and fixed effects with robust standard errors; linear mixed models, random-effects probit, GEE, random- and fixed-effects Poisson, dynamic panel-data models, and instrumental-variables regression; panel unit-root tests; AR(1) disturbances
Generalized linear models (GLMs)
ten link functions, user-defined links, seven distributions, ML and IRLS estimation, nine variance estimators, seven residuals
Nonparametric methods
Wilcoxon-Mann-Whitney, Wilcoxon signed ranks and Kruskal-Wallis tests; Spearman and Kendall correlations; Kolmogorov-Smirnov tests; exact binomial CIs; survival data; ROC analysis; smoothing; bootstrapping
Exact statistics
exact logistic and Poisson regression, exact case-control statistics, binomial tests, Fisher's exact test for r × c tables
ANOVA/MANOVA
balanced and unbalanced designs; factorial, nested, and mixed designs; repeated measures; marginal means; contrasts
Multivariate methods
factor analysis, principal components, discriminant analysis, rotation, multidimensional scaling, Procrustean analysis, correspondence analysis, biplots, dendrograms, user-extensible analyses
Cluster analysis
hierarchical clustering; kmeans and kmedian nonhierarchical clustering; dendrograms; stopping rules; user-extensible analyses
Resampling and simulation methods
bootstrapping, jackknife and Monte Carlo simulation; permutation tests
Tests, predictions, and effects
Wald tests; LR tests; linear and nonlinear combinations, predictions and generalized predictions, marginal means, least-squares means, adjusted means; marginal and partial effects; forecast models; Hausman tests
Graphics
line charts, scatterplots, bar charts, pie charts, hi-lo charts, regression diagnostic graphs, survival plots, nonparametric smoothers, distribution Q-Q plots








Survey methods
multistage designs; bootstrap, BRR, jackknife, linearized, and SDR variance estimation; poststratification; DEFF; predictive margins; means, proportions, ratios, totals; summary tables; regression, instrumental variables, probit, Cox regression
Survival analysis
Kaplan-Meier and Nelson-Aalen estimators,; Cox regression (frailty); parametric models (frailty); competing risks; hazards; time-varying covariates; left- and right-censoring, Weibull, exponential, and Gompertz analysis
Epidemiology
standardization of rates, case–control, cohort, matched case-control, Mantel-Haenszel, pharmacokinetics, ROC analysis, ICD-9-CM
Time series
ARIMA; ARFIMA; ARCH/GARCH; VAR; VECM; multivariate GARCH; unobserved components model; dynamic factors; state-space models; business calendars; correlograms; periodograms; forecasts; impulse-response functions; unit-root tests; filters and smoothers; rolling and recursive estimation
Multiple imputation
nine univariate imputation methods; multivariate normal imputation; chained equations; explore pattern of missingness; manage imputed datasets; fit model and pool results; transform parameters; joint tests of parameter estimates; predictions
Simple maximum likelihood
specify likelihood using simple expressions; no programming required; survey data; standard, robust, bootstrap, and jackknife SEs; matrix estimators
Programmable maximum likelihood
user-specified functions; NR, DFP, BFGS, BHHH; OIM, OPG, robust, bootstrap, and jackknife SEs; Wald tests; survey data; numeric or analytic derivatives
Other statistical methods
kappa measure of interrater agreement; Cronbach's alpha; stepwise regression; tests of normality
Programming features
adding new commands; command scripting; object-oriented programming; menu and dialog-box programming; Project Manager; plugins
Matrix programming-Mata
interactive sessions, large-scale development projects, optimization, matrix inversions, decompositions, eigenvalues and eigenvectors, LAPACK engine, real and complex numbers, string matrices, interface to Stata datasets and matrices, numerical derivatives, object-oriented programming
Internet capabilities
ability to install new commands, web updating, web file sharing, latest Stata news
Accessibility
Section 508 compliance, accessibility for persons with disabilities
Sample session
A sample session of Stata for Mac, Unix, or Windows.
Community-contributed commands
User-written commands for meta-analysis, data management, survival, econometrics
Graphical user interface
menus and dialogs for all features; Data Editor; Variables Manager; Graph Editor; Project Manager; Do-file Editor; Clipboard Preview Tool; multiple preference sets
Graphics
line charts; scatterplots; bar charts; pie charts; hi-lo charts; contour plots; GUI Editor; regression diagnostic graphs; survival plots; nonparametric smoothers; distribution Q-Q plots
Documentation
20 manuals20 manuals; 11,000+ pages; seamless navigation; thousands of worked examples; methods and formulas; references; 11,000+ pages; seamless navigation; thousands of worked examples; methods and formulas; references
Power and sample size
power; sample size; effect size; minimum detectable effect; means; proportions; variances; correlations; case-control studies; cohort studies; survival analysis; balanced or unbalanced designs; results in tables or graphs
Treatment effects
inverse probability weight (IPW); doubly robust methods; propensity score matching; regression adjustment; covariate matching; multilevel treatments; average treatment effects (ATEs); average treatment effects on the treated (ATETs); potential-outcome means (POMs)
SEM (Structural equation modeling)
graphical path diagram builder; standardized and unstandardized estimates; modification indices; direct and indirect effects; continuous, binary, count, and ordinal outcomes (GLM); multilevel models; random slopes and intercepts; factors scores, empirical Bayes, and other predictions; groups and tests of invariance; goodness of fit; handles MAR data by FIML; correlated data
Functions
statistical; random-number; mathematical; string; date and time
Embedded statistical computations
Numerics by Stata
Contrasts, pairwise comparisons, and margins
compare means, intercepts, or slopes; compare to reference category, adjacent category, grand mean, etc.; orthogonal polynomials; multiple comparison adjustments; graph estimated means and contrasts; interaction plots
GMM an nonlinear regression
generalized method of moments (GMM); nonlinear regression